
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
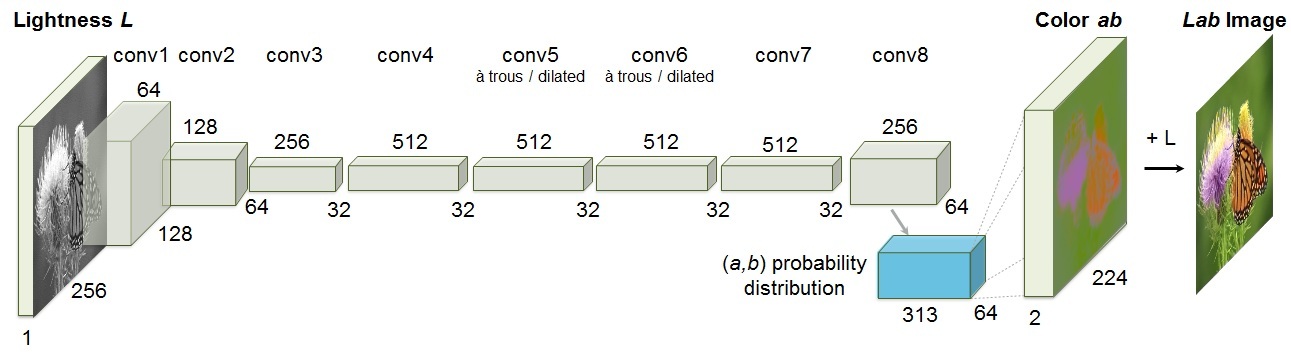
 |
| ECCV Talk 10/2016, also hosted on [VideoLectures] |
 |
 |
Zhang, Isola, Efros. Colorful Image Colorization. In ECCV, 2016 (oral). (hosted on arXiv) |
 (hover for our results; click for full images) extention of Figure 15 from our paper |
 (hover for our results; click for full images) Figure 16 from our paper |
 (hover for our results; click for full images) Figure 17 from our paper |
 (hovering shows our results; click for additional examples) |
 (hovering shows our results; click for additional examples) |
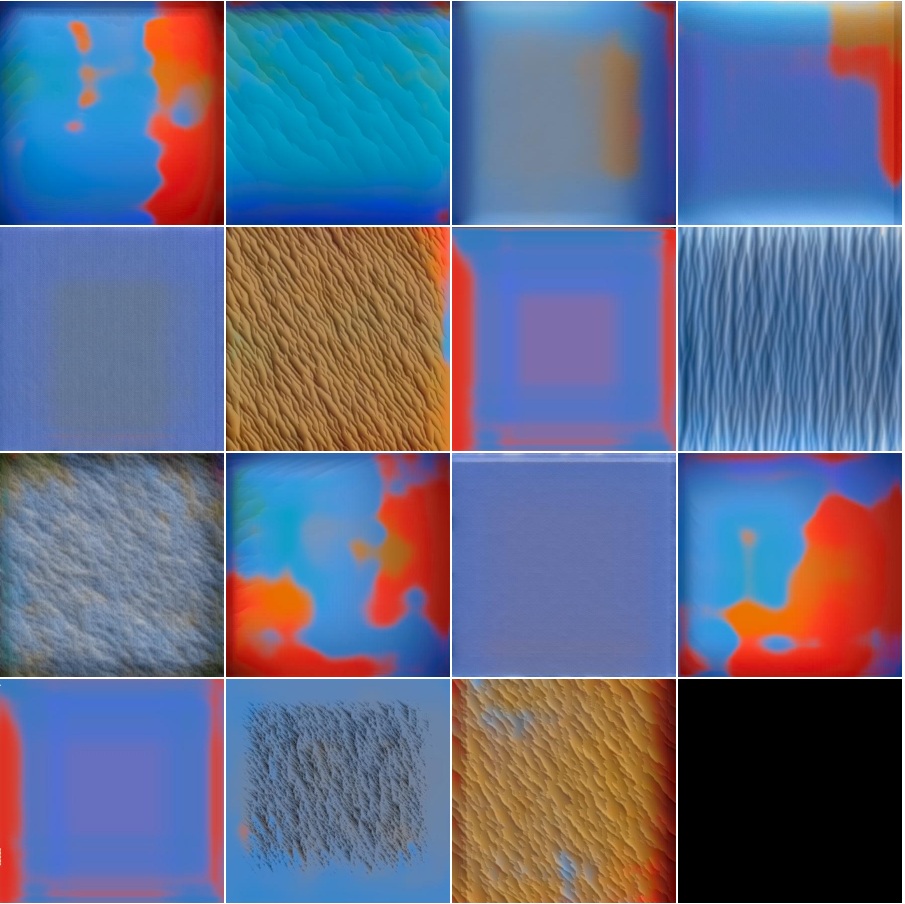 conv1_2 |
 conv2_1 |
 conv2_2 |
 conv3_1 |
 conv3_2 |
 conv3_3 |
 conv4_1 |
 conv4_2 |
 conv4_3 |
 conv5_1 |
 conv5_2 |
 conv5_3 |
 conv6_1 |
 conv6_2 |
 conv6_3 |
 conv7_1 |
 conv7_2 |
 conv7_3 |
User-Generated Examples |
Recent Related WorkGustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning Representations for Automatic Colorization. In ECCV 2016. [PDF][Website] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification. In SIGGRAPH, 2016. [PDF][Website] Ryan Dahl. Automatic Colorization. Jan 2016. [Website] Aditya Deshpande, Jason Rock and David Forsyth. Learning Large-Scale Automatic Image Colorization. In ICCV, Dec 2015. [PDF][Website] Zezhou Cheng, Qingxiong Yang, and Bin Sheng. Deep Colorization. In ICCV, Dec 2015. [PDF] |
Acknowledgements |



















{kind=link}