We propose split-brain autoencoders, a straightforward modification of the traditional autoencoder architecture, for unsupervised representation learning. The method adds a split to the network, resulting in two disjoint sub-networks. Each sub-network is trained to perform a difficult task -- predicting one subset of the data channels from another. Together, the sub-networks extract features from the entire input signal. By forcing the network to solve cross-channel prediction tasks, we induce a representation within the network which transfers well to other, unseen tasks. This method achieves state-of-the-art performance on several large-scale transfer learning benchmarks.
Method
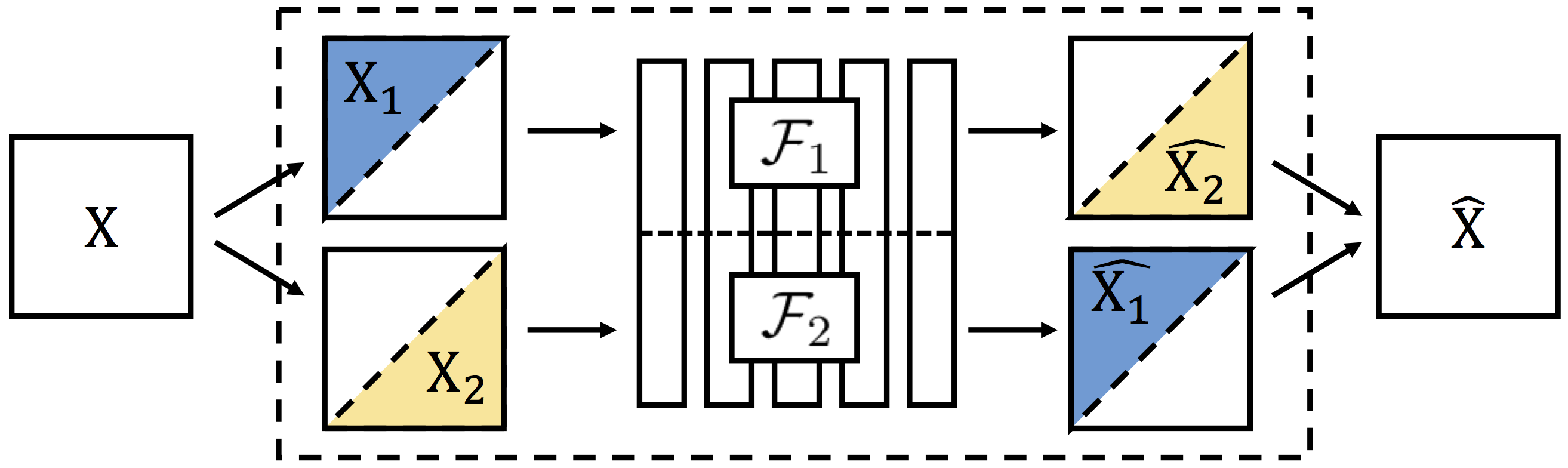
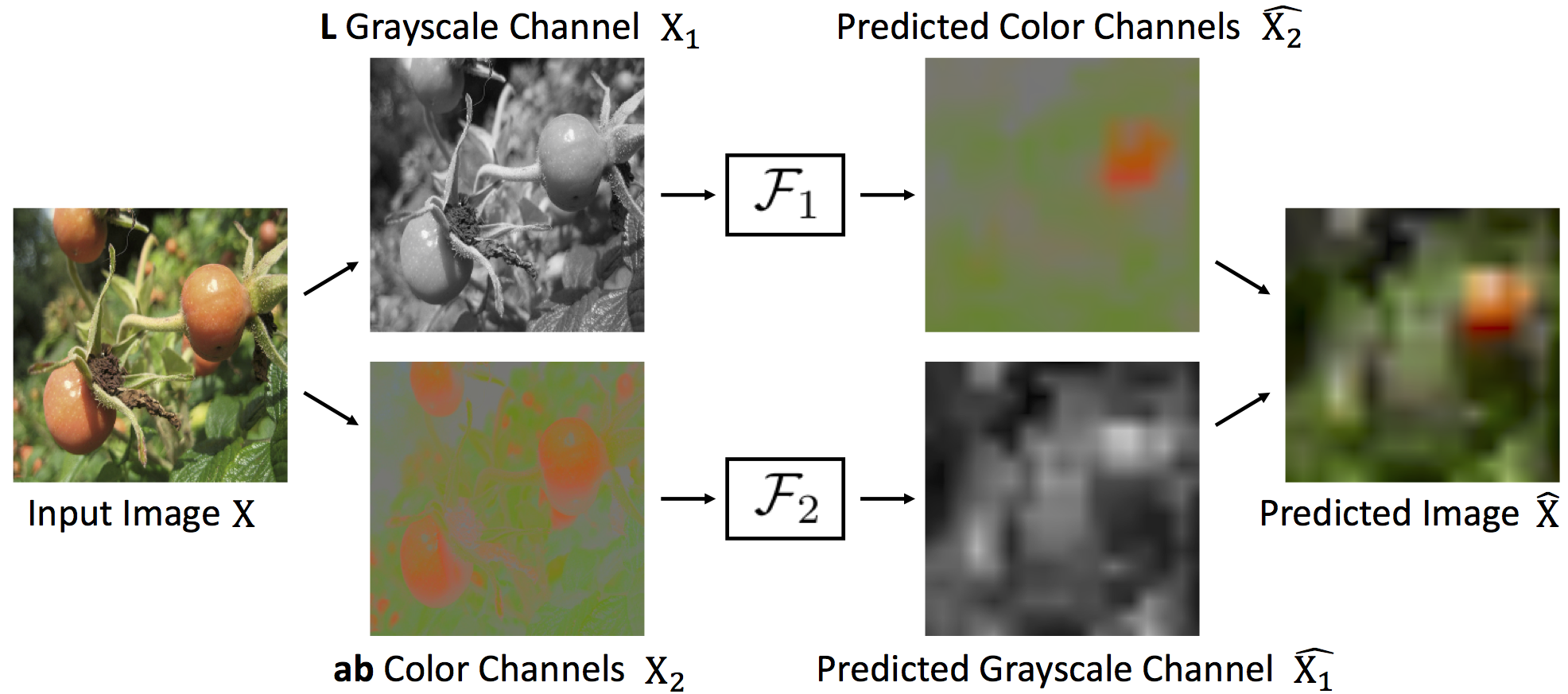
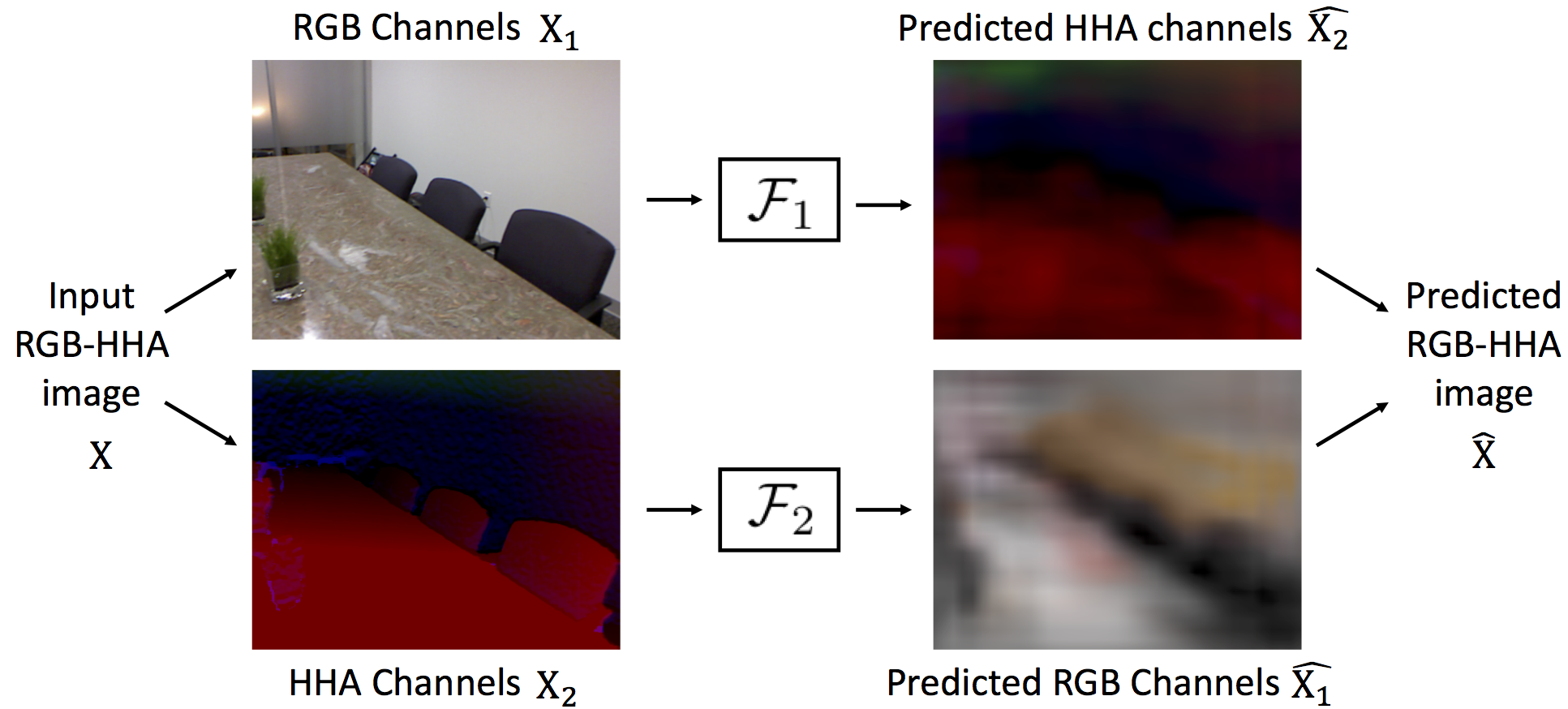
To perform unsupervised pretraining, we split a network in half in the channel direction to produce two disjoint subnetworks. Each subnetwork is then trained to perform prediction on one subset of data from another subset. (Left) Images Half of the network predicts color channels from grayscale, and the other half predicts grayscale from color. (Right) RGB-D Images Half of the network predicts depth from images, and the other half predicts images from depth. Please see Section 3 of the full paper for additional details.
We show that we can learn features in an unsupervised framework, simply by predicting channels of raw data from other channels of raw data.
Feature Evaluation Results
Here, we show feature evaluation results on large-scale RGB images, which are described in Section 4.1 of the paper. Results on the RGB-D domain are in Section 4.2.
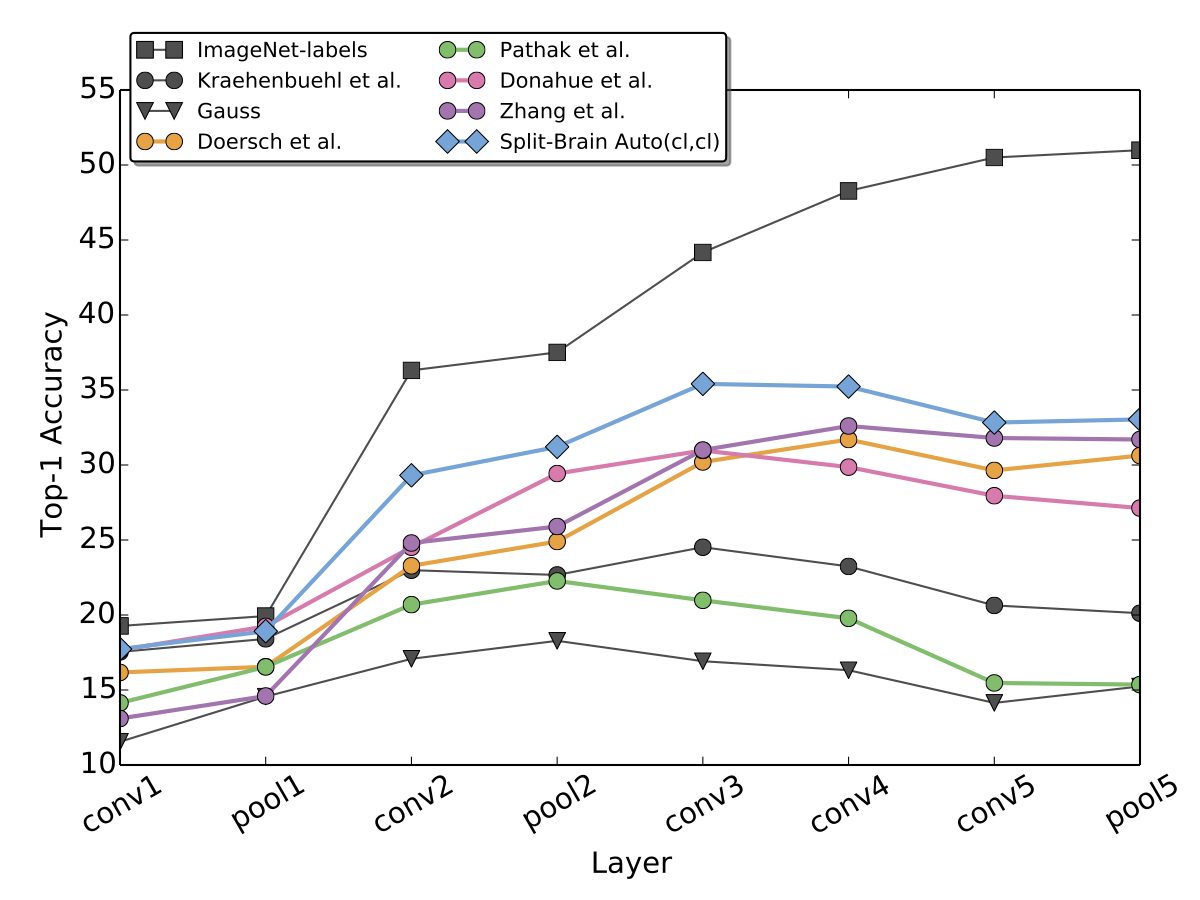
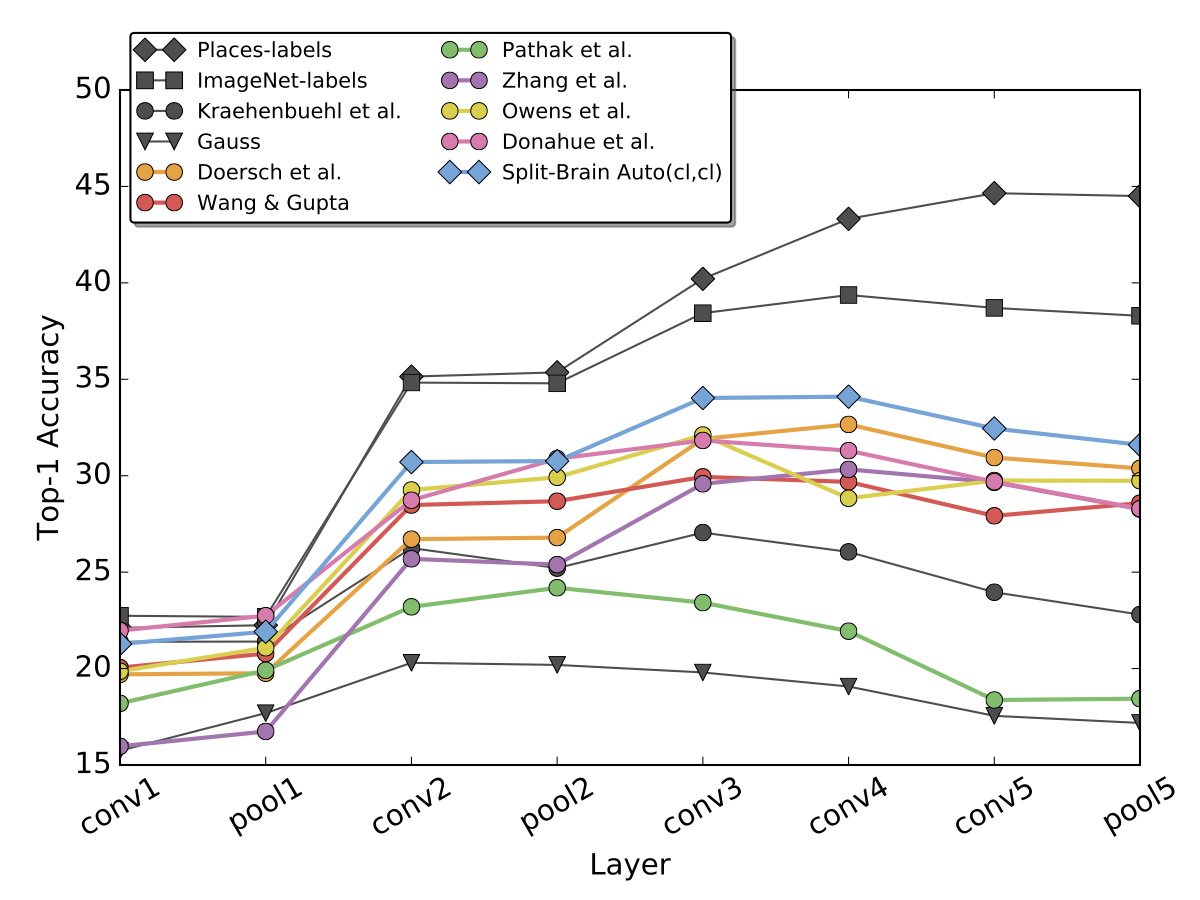
The first group of tests are linear classifiers for semantic classification on each layer in the network. We freeze pre-trained AlexNet representations, spatially resize feature maps so that all layers have approximately 9000 dimensions, and train multinomial logistic regression classifiers on the (Left) ImageNet and (Right) Places datasets. ImageNet-labels and Places-labels are networks which are pre-trained in a supervised regime. All other methods shown are unsupervised. Method Split-Brain Auto (cl,cl) is our proposed method, and performs well compared to previous unsupervised/self-supervised methods.
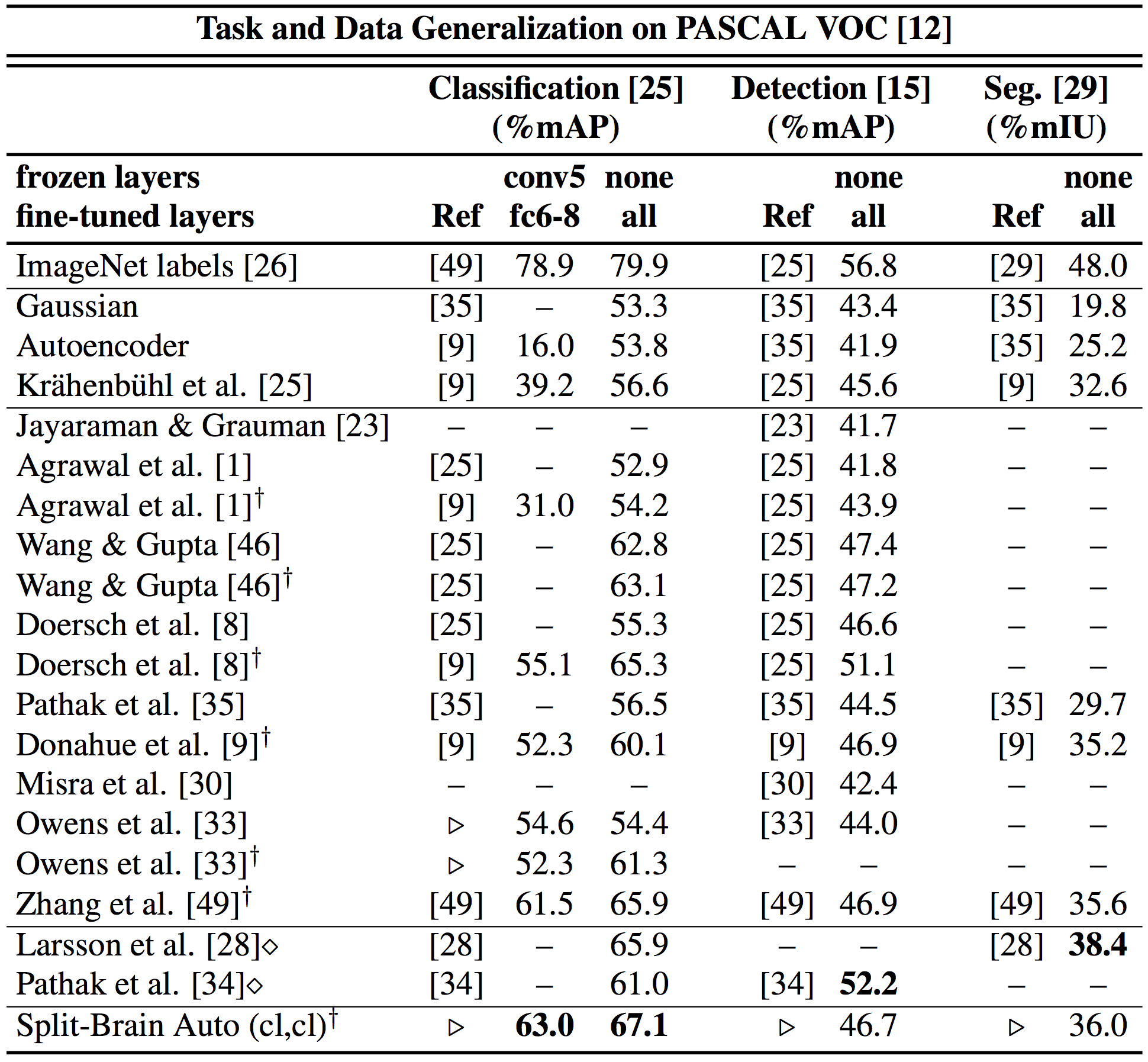
We also show performance on several commonly used transfer learning benchmarks on the PASCAL VOC dataset. The table below is Table 4 from the paper, and additional details can be found in Section 4.1.1.
Paper
R. Zhang, P. Isola, A. A. Efros. Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction.
In CVPR, 2017. (hosted on arXiv)
The GitHub page has scripts for fetching our model, and a slightly modified version of Caffe which does color pre-processing (if so desired). We recommend going to the GitHub page and following instructions in the readme.
We thank members of the Berkeley Artificial Intelligence Research Lab (BAIR), in particular Andrew Owens, for helpful discussions, as well as Saurabh Gupta for help with RGB-D experiments. This research was supported, in part, by Berkeley Deep Drive (BDD) sponsors, hardware donations by NVIDIA Corp and Algorithmia, an Intel research grant, NGA NURI, NSF IIS-1633310, and NSF SMA-1514512. Thanks Obama.